demo_model(random)
The criteria implemented come from this paper.
Found permutation search CUDA kernels [ASP][Info] permutation_search_kernels can be imported. —
def Reducer(
args:VAR_POSITIONAL, kwargs:VAR_KEYWORD
):
Initialize self. See help(type(self)) for accurate signature.
def Normalizer(
args:VAR_POSITIONAL, kwargs:VAR_KEYWORD
):
Initialize self. See help(type(self)) for accurate signature.
def Criteria(
f:Callable[[torch.Tensor], torch.Tensor], # Function that transforms weights (e.g., torch.abs, torch.square)
reducer:Callable=<function Reducer.mean>, # Method to reduce dimensions ('mean' or 'sum')
normalizer:Callable | None=None, # Method to normalize scores (None, 'sum', 'standardization', 'mean', 'max', 'gaussian')
needs_init:bool=False, # Whether this criteria needs the initial weights
needs_update:bool=False, # Whether this criteria needs to track weight updates between iterations
output_fn:Callable[[torch.Tensor, torch.Tensor], torch.Tensor] | None=None, # Function to combine current and reference weights
return_init:bool=False, # Whether to return the transformed initial weights instead of final output
):
Evaluates neural network parameters based on various criteria for pruning
demo_model(random)
demo_model(large_final)
demo_model(squared_final)
demo_model(small_final)
demo_model(large_init)
demo_model(small_init)
demo_model(large_init_large_final, 80)
demo_model(small_init_small_final)
demo_model(magnitude_increase, 60)
demo_model(movement)
movmag = init_based_criteria(noop, output_fn=lambda x,y: torch.abs(torch.mul(x, torch.sub(x,y))))demo_model(movmag)
The following criteria use an updating value of the weights, i.e. the value from the previous iteration of training, instead of the initialization value to better capture the training dynamics.
demo_model(updating_magnitude_increase)
demo_model(updating_movement, 50)
demo_model(updating_movmag)
The following criteria use input activation statistics collected during a calibration pass, providing data-aware importance scoring.
Wanda (Sun et al. ICLR 2024) scores weight importance as |W| × ‖X‖₂ — the product of weight magnitude and input activation L2 norm. Best for one-shot post-training sparsification. Requires calibration data passed via Sparsifier(data=...).
updating_magnitude_increase = Criteria(torch.abs, needs_update=True, output_fn= lambda x,y: torch.abs(torch.sub(x,y)))
demo_model(updating_magnitude_increase)
updating_magnitude_increase = Criteria(torch.abs, needs_update=True, output_fn= lambda x,y: torch.sub(x,y))
demo_model(updating_magnitude_increase)
updating_magnitude_increase = Criteria(torch.square, needs_update=True, output_fn= lambda x,y: torch.abs(torch.sub(x,y)))
demo_model(updating_magnitude_increase)
updating_movmag = Criteria(noop, needs_update=True, output_fn=lambda x,y: torch.abs(torch.mul(x, torch.sub(x,y))))
demo_model(updating_movmag)
updating_movmag = Criteria(noop, needs_update=True, output_fn=lambda x,y: torch.abs(torch.mul(torch.square(x), torch.sub(x,y))))
demo_model(updating_movmag)
updating_movmag = Criteria(torch.square, needs_update=True, output_fn=lambda x,y: torch.abs(torch.mul(x, torch.sub(x,y))))
#updating_movmag = Criteria(noop, needs_update=True, output_fn=lambda x,y: torch.mul(x, torch.sub(x,y)))
demo_model(updating_movmag)
updating_movmag = Criteria(torch.abs, needs_update=True, output_fn=lambda x,y: torch.abs(torch.mul(x, torch.sub(x,y))))
#updating_movmag = Criteria(noop, needs_update=True, output_fn=lambda x,y: torch.mul(x, torch.sub(x,y)))
demo_model(updating_movmag, 30)
updating_movmag = Criteria(torch.abs, needs_update=True, output_fn=lambda x,y: torch.mul(x, torch.sub(x,y)))
demo_model(updating_movmag, 80)
updating_movmag = Criteria(torch.square, needs_update=True, output_fn=lambda x,y: torch.mul(x, torch.sub(x,y)))
demo_model(updating_movmag)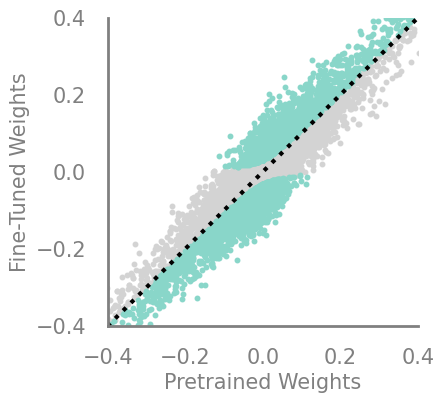
updating_movmag = Criteria(noop, needs_update=True, output_fn=lambda x,y: torch.mul(x, torch.sub(x,y)))
demo_model(updating_movmag)
updating_movement = Criteria(noop, needs_update=True, output_fn= lambda x,y: torch.abs(torch.sub(-x,y)))
demo_model(updating_movement, 50)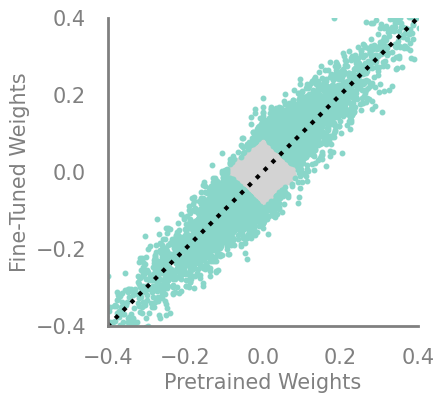
updating_movement = Criteria(torch.abs, needs_update=True, output_fn= lambda x,y: torch.abs(torch.sub(-x,y)))
demo_model(updating_movement)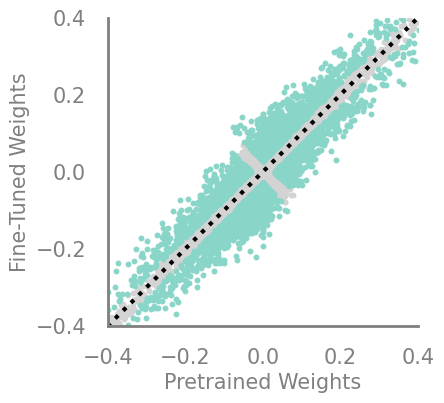
updating_movement = Criteria(torch.abs, needs_update=True, output_fn= lambda x,y: torch.abs(torch.cosh(torch.sub(x,y))))
demo_model(updating_movement)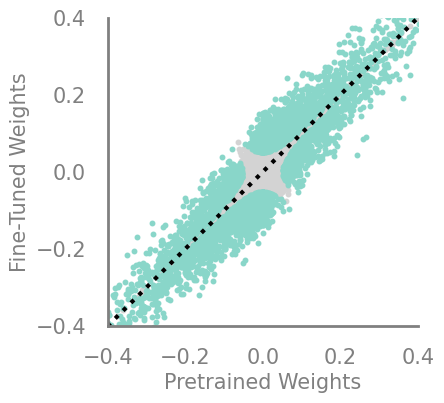
updating_movement = Criteria(torch.square, needs_update=True, output_fn= lambda x,y: torch.abs(torch.sub(x,y)))
demo_model(updating_movement)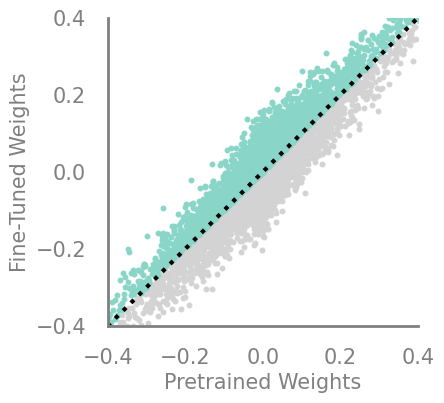
updating_movement = Criteria(noop, needs_update=True, output_fn= lambda x,y: torch.sub(x,y))
demo_model(updating_movement)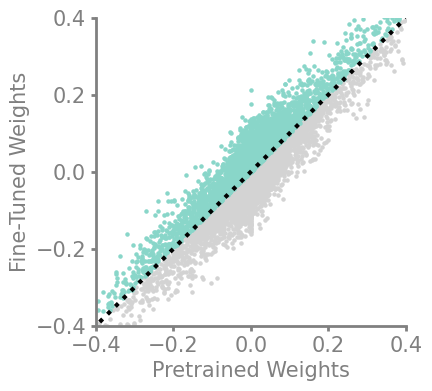
mine = partial(torch.pow, exponent=4)large_final = Criteria(torch.frac)
demo_model(large_final)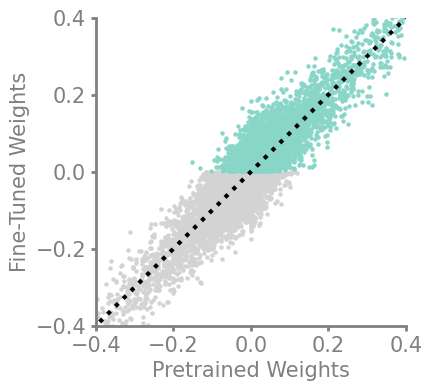
scores = torch.randn(100).abs()
normed = Normalizer.standardization(scores)| Criteria | Data-Aware | Best For | Requires |
|---|---|---|---|
| large_final | No | General-purpose magnitude pruning | Nothing |
| wanda | Yes | Post-training one-shot pruning | Calibration data |
| movement | No | During-training pruning | Initial weights |
| grad_crit | No | Gradient-informed pruning | Gradients |
| random | No | Baseline comparison | Nothing |